





I. Introduction▲
La disponibilité des ressources est au centre des préoccupations actuelles d'un administrateur de bases de données afin d'assurer le bon fonctionnement du système d'information de l'entreprise. S'assurer de la disponibilité des ressources c'est avant tout la surveillance du bon fonctionnement des différents éléments physiques d'un serveur, mais aussi celle de la charge de travail que subit ce serveur. Comment s'assurer qu'une requête SQL ne monopolisera pas l'ensemble des ressources du serveur ? Comment fixer certaines limites pour anticiper l'apparition de goulets d'étranglement ? Le gouverneur de ressources permet de répondre à ces différentes problématiques.
II. Architecture▲
Le gouverneur de ressources est constitué de trois entités qui introduisent trois nouveaux concepts que sont les pools de ressources, les groupes de charge de travail et les fonctions de classifications. Dans le contexte d'utilisation du gouverneur de ressources, le traitement d'une connexion entrante se fait sous forme de flux. Les étapes de ce flux sont les suivantes :
- une demande entrante est créée (création d'une session) ;
- cette demande est classée (composant de classification) ;
- la demande est acheminée vers un groupe de charge de travail ;
- le groupe de charge de travail concerné utilise un pool de ressources qui lui est associé ;
- le pool de ressources définit les valeurs limites de consommation des ressources que la demande pourra utiliser.
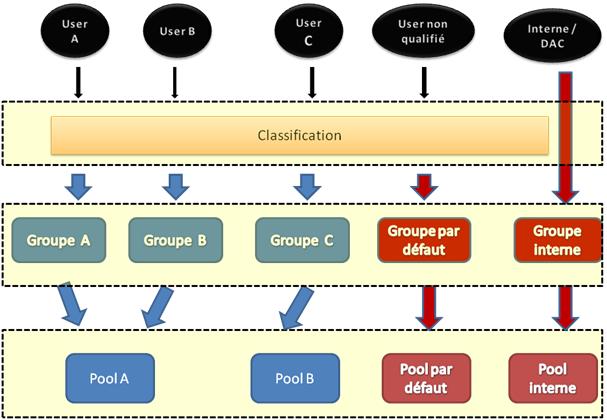
Ce flux est donc traité à différents niveaux par trois entités qui composent le gouverneur de ressources. Connaître le fonctionnement de chacune de ces entités est donc primordial.
II-A. Fonction de classification▲
Grâce à une fonction utilisateur spécifique utilisée par le gouverneur de ressources, il est possible d'établir des règles qui classent les demandes entrantes et ensuite les acheminent vers les groupes de charge de travail correspondants. Il existe également des règles internes utilisées par le moteur SQL qui effectuent les mêmes actions vers le groupe de charge de travail interne.
La classification d'une demande s'effectue immédiatement après la phase d'authentification et éventuellement après l'exécution des déclencheurs DDL sur des événements de type LOGIN. Comme il est dit précédemment, c'est une fonction utilisateur qui assurera ce rôle de classification. Cette fonction doit être créée dans la base master et à l'aide des fonctions système natives de SQL Server (LOGIN_NAME(), HOST_NAME(), APP_NAME(), LOGIN_PROPERTY(), CONNECTIONPROPERTY(), IS_MEMBER(), IS_SRVROLEMEMBER() ), il est possible de trouver diverses solutions ou axes de classification d'une demande. Le code TSQL d'une fonction de classification peut être plus ou moins complexe selon les règles de classification implémentée, mais il faut garder à l'esprit qu'elle constitue le principal point d'entrée de toutes les demandes et devient donc un élément générateur de problèmes de performances. En d'autres termes, plus le code de la fonction utilisateur est simple et optimisé plus le traitement des demandes se fera rapidement. Il est possible de mesurer les performances liées à cette phase de classification. Nous y reviendrons plus tard dans l'article.
De plus la fonction de classification doit respecter les conditions suivantes :
- elle doit toujours retourner un type NVARCHAR(128) avec une collation sensible à la casse pour être en concordance avec les types de paramètres utilisés par le gouverneur de ressources ;
- l'option SCHEMABINDING doit être utilisée lors de la création de cette fonction. Par conséquent une fois celle-ci mise en place il peut être difficile de changer les objets sous-jacents en liaison avec cette fonction ;
- une fois la fonction liée au gouverneur de ressources, il est impossible de la supprimer. La seule façon de supprimer cette fonction est de rompre en premier la liaison avec le gouverneur de ressources par le biais de l'instruction ALTER RESOURCE GOVERNOR.
La classification devient active lorsque le gouverneur de ressources est en état de fonctionnement. Dans le cas contraire, toutes les demandes sont directement dirigées vers le pool par défaut
II-B. Groupes de charge de travail▲
Un groupe de charge de travail est un conteneur logique qui rassemble les demandes entrantes qui possèdent les mêmes caractéristiques. L'avantage des groupes de travail est double : ils permettent d'établir une même stratégie de répartition des ressources pour toutes les demandes d'un même groupe et d'en analyser la consommation.
Deux groupes de charges de travail existent par défaut : le groupe par défaut et le groupe interne. Le groupe par défaut mutualise toutes les demandes entrantes pour lesquelles il n'existe pas de critère de classement ou que le groupe d'acheminement de la demande est absent. De manière générale, un échec de classification d'une demande engendre un transfert automatique de celle-ci dans le groupe par défaut.
L'utilisation du groupe interne est réservée exclusivement pour le moteur SQL ou pour une connexion DAC (Dedicated Adminstrator Connection). Un utilisateur ne peut donc pas l'utiliser pour ses besoins, mais il peut en surveiller l'utilisation et la consommation.
La création d'un pool se fait soit de façon graphique à l'aide de SQL Server Management Studio soit par script à l'aide de l'instruction CREATE WORKLOAD GROUP. Il existe six options de paramétrage.
IMPORTANCE : chaque groupe de charge de travail est associé à une notion d'importance qui peut être fixée à LOW, MEDIUM ou HIGH. L'importance définit un ratio de ressources CPU disponible pour un groupe de charge de travail par rapport aux autres groupes à l'intérieur d'un même pool de ressources. Cette notion d'importance est différente du concept de priorité classique que nous connaissons. En effet, l'ordonnanceur va distribuer les différentes tâches d'exécution des groupes de charge de travail en fonction de ce ratio. Chaque importance correspond à une valeur numérique (1 pour LOW, trois pour MEDIUM et 9 pour HIGH). Par exemple pour un groupe A qui possède une importance définie à MEDIUM et pour un groupe B une importance définie à LOW à l'intérieur d'un même pool de ressources, le ratio est de 1 pour 3, ce qui signifie que l'ordonnanceur tentera d'exécuter trois fois plus souvent les sessions exécutables du groupe A que les sessions exécutables du groupe B. Par conséquent, les ressources que pourra acquérir le groupe A seront plus importantes que celles du groupe B pour une charge de travail équivalente. Le paramètre d'importance reste local à un pool de ressources ce qui signifie qu'un groupe de travail peut affecter un autre groupe de travail à l'intérieur d'un même pool, mais ne peut pas affecter un autre groupe de travail dans un autre pool.
MAX_DOP : cette option spécifie le degré de parallélisme maximum d'une requête. Elle s'apparente à l'option MAX_DOP utilisée par les indicateurs de requête (WITH MAX_DOP), mais ne fonctionne pas de la même manière. En effet si l'option MAX_DOP utilisée par les indicateurs de requête prend la valeur 1, aucun plan d'exécution parallèle ne sera généré ce qui n'est pas le cas de l'option MAX_DOP utilisée par le groupe de ressources. En effet un plan parallèle pourra être généré, mais les instructions seront sérialisées. Nous reviendrons sur ce point un peu plus loin dans l'article. D'autres considérations sont à prendre en compte avec cette option :
- une option MAX_DOP utilisée par un indicateur de requête sera valable tant que celle-ci n'excédera pas une option MAX_DOP définie dans un groupe de travail. Par exemple une option MAX_DOP définie à 2 par un indicateur de requête et qui autorise l'utilisation de 2 processeurs ne sera pas exécutée en parallèle si une option MAX_DOP du groupe de charge de travail est définie à 1 pour la requête concernée ;
- si le plan d'exécution en cache d'une requête est marqué comme étant en série, il ne pourra être reconverti en tant que plan parallèle qu'au moment d'une recompilation et ceci indépendamment des différentes options MAX_DOP et max degree of parallelism ;
- une fois que le degré de parallélisme est paramétré pour un groupe donné, celui-ci ne peut être diminué que si une pression mémoire existe. En effet la reconfiguration de l'option MAX_DOP d'un groupe de charge de travail n'est pas visible dans la file d'attente d'allocation mémoire.
REQUEST_MAX_MEMORY_GRANT_PERCENT : cette option spécifie le pourcentage de mémoire maximum que peut utiliser une seule requête. Ce pourcentage est relatif à la quantité de mémoire définie dans le pool avec l'option MAX_MEMORY_PERCENT. La valeur par défaut est de 25 %. De la même manière que l'option de pool de ressources MAX _MEMORY _PERCENT la quantité de mémoire disponible concerne uniquement le cache d'exécution des requêtes.
Lorsqu'une demande de ressources mémoire est effectuée au-delà des limites spécifiées par l'option REQUEST_MAX_MEMORY_GRANT_PERCENT le gouverneur de ressources effectue différentes opérations selon le groupe de charge de travail concerné. Pour les groupes de charge de travail définis par l'utilisateur, le degré de parallélisme est diminué tant que les besoins en mémoire ne sont pas satisfaits ou bien que celui-ci atteint la valeur 1. Si une quantité de mémoire est encore nécessaire une l'erreur 8657 est déclenchée. Pour les groupes de travail par défaut ou internes, la quantité supplémentaire de mémoire est allouée directement tant que celle-ci est disponible et n'est pas réservée par d'autres pools de ressources. Dans ce cas l'erreur 8645 est déclenchée.
Le paramétrage de cette option doit être fait avec parcimonie. En effet, une valeur élevée permettrait à une seule requête de pouvoir bénéficier d'une quantité plus importante de mémoire et de s'exécuter de façon plus optimale en réduisant les concurrences d'allocation de mémoire par d'autres requêtes, mais en contrepartie il serait impossible d'exécuter simultanément la même requête plusieurs fois. En d'autres termes une requête qui monopoliserait le maximum de ressources mémoire paramétrée pourrait être exécutée trois fois simultanément au maximum (3 X 25 = 75 %) alors que si cette option prenait une valeur plus élevée par exemple 70, cela signifie qu'il ne serait alors plus possible de lancer deux fois simultanément cette même requête qui prendrait cette fois-ci plus de 70 % des ressources à elle seule. Dans ce cas c'est l'erreur 8657 qui serait probablement déclenchée. En revanche une valeur à 0 empêche toute opération de tri ou de hash lors de l'exécution d'une requête.
GROUP_MAX_REQUESTS : cette option spécifie le nombre de requêtes simultanées qu'il est possible d'exécuter dans un groupe de charge de travail. Si plusieurs requêtes sont exécutées simultanément, les deux dernières seront placées dans une file d'attente tant que la 1re requête est en cours d'exécution. Pour éviter les cas de blocage (deadlocks), SQL Server peut outrepasser cette option.
REQUEST_MAX_CPU_TIME_SEC : cette option spécifie la quantité maximale de temps CPU qu'une requête peut utiliser. Contrairement à l'option de serveur cost limit qui empêche l'exécution d'une requête qui dépasse la valeur de seuil définie, le gouverneur de ressources laisse la requête s'exécuter, mais déclenchera un événement de dépassement de seuil. Ce dépassement se présente sous la forme d'un événement qu'il est possible de capturer avec SQL Profiler.
II-C. Pools de ressources▲
Un pool de ressources permet de définir les limites ou d'imposer des contraintes d'utilisation des ressources du serveur. Les ressources concernées sont les processeurs et la mémoire. Il n'est pas possible d'effectuer le même pilotage concernant les entrées/sorties du sous-système disque pour le moment.
Un pool de ressources est divisé en deux parties distinctes :
- une partie qui permet le partage des ressources avec d'autres pools. Cette partie indique les ressources disponibles qui peuvent être accaparées par d'autres pools si ceux-ci en ont besoin ;
- une autre partie qui garantit un minimum de ressources au(x) groupe(s) de charge de travail associé(s). Cette partie ne peut donc pas se chevaucher et être partagée avec les autres pools.
Il est possible de configurer 18 pools au total plus les deux pools créés par défaut (pool par défaut et pool interne). La création d'un pool se fait soit de façon graphique par SQL Server Management Studio soit par script à l'aide de l'instruction CREATE RESOURCE POOL. Il existe quatre options de paramétrage :
MIN_CPU_PERCENT : cette option permet lorsqu'il existe une contention CPU de garantir un pourcentage minimum de ressources pour les requêtes actives dans un pool. Il est important de bien comprendre ceci. Le gouverneur de ressources équilibre les ressources disponibles pour l'ensemble des threads actifs à l'intérieur de ce pool. Les valeurs du paramètre MIN_CPU_PERCENT peuvent être comprises entre 0 et 100, mais la somme des valeurs de l'ensemble des pools du gouverneur de ressources ne peut pas être supérieure à 100 ;
MAX_CPU_PERCENT : lorsqu'une contention CPU existe ce paramètre garantit que l'ensemble des threads actifs dans le pool ne consomme pas de ressources au-delà d'un certain seuil. Ce paramètre ne peut pas prendre la valeur 0. La valeur du paramètre MAX_CPU_PERCENT doit être supérieure ou égale à la valeur du paramètre MIN_CPU_PERCENT ;
MIN_MEMORY_PERCENT : ce paramètre garantit un certain pourcentage de ressources de mémoire disponible pour un pool dans tous les cas. En d'autres termes même s'il n'existe aucune contention mémoire, une quantité de mémoire sera quand même réservée à l'utilisation de ce pool même si aucune activité n'est présente dans le pool. Un mauvais paramétrage aurait pour conséquence de réserver de la ressource mémoire inutilement alors que d'autres pools pourraient en avoir besoin. De la même manière que le paramètre MIN_CPU_PERCENT, les valeurs peuvent être comprises entre 0 et 100. La somme des valeurs de l'ensemble des pools pour ce paramètre ne peut pas excéder 100 % ;
MAX_MEMORY_PERCENT : ce paramètre garantit que les ressources mémoire consommées par l'ensemble des threads actifs dans le pool ne dépassent pas le seuil configuré. Les valeurs peuvent être comprises entre 0 et 100. La valeur de ce paramètre doit être supérieure ou égale à la valeur du paramètre MIN_MEMORY_PERCENT. Il est important de préciser ici que seule la mémoire concernant le cache d'exécution est concernée.
Important : il n'existe aucune restriction pour le pool interne et pour une connexion de type DAC. Le pool par défaut, quant à lui, peut être personnalisé, mais ne peut pas être supprimé.
III. Dimensionnement des pools de ressources▲
Le dimensionnement des pools de ressources et des groupes de charge de travail est une part importante dans le processus de mise en place du gouverneur de ressources. L'enjeu est ici de déterminer les ressources nécessaires à allouer en fonction des besoins métier. Bien entendu, il est possible de modifier n'importe quel paramètre d'un pool de ressources ou d'un groupe de charge de travail a posteriori. Comme nous l'avons vu un pool de ressources possède deux parties distinctes, dont une partie qui est partagée avec les autres pools et une autre partie fixe qui lui est réservée exclusivement. Les valeurs MIN et MAX ont ici toute leur importance, car elles permettent de calculer les ressources partagées d'un pool d'une part et le maximum de ressources effectif que pourra utiliser ce même pool d'autre part.
La décomposition de ce calcul est la suivante : (extraite de la BOL SQL Server)
- Min (X, Y) : plus petite valeur entre X et Y.
- Sum(X) : somme des valeurs de X pour tous les pools.
- Total partagé % : 100 - Sum(X).
- % MAX EFFECTIF : Min (X, Y).
- % PARTAGE : % MAX EFFECTIF - MIN(X, Y).
Voici un exemple de dimensionnement avec deux pools utilisateurs plus les deux pools créés par défaut avec SQL Server :
|
Pool |
% MIN |
% MAX |
% MAX EFFECTIF |
% PARTAGE |
|
|---|---|---|---|---|---|
|
Interne |
0 |
100 |
10 |
0 |
MIN et MAX non applicables pour ce pool |
|
Défaut |
0 |
100 |
30 |
30 |
MAX EFF = min (100, 100 - (20 + 50)) % PARTAGE = MAX EFF - MIN |
|
Pool 1 |
20 |
100 |
50 |
30 |
MAX EFF = min (100, 100 - 50) % PARTAGE = MAX EFF - MIN |
|
Pool 2 |
50 |
70 |
70 |
20 |
MAX EFF = min (70, 100 - 20) % PARTAGE = MAX EFF - MIN |
L'ajout d'un 3e pool peut avoir des répercussions sur les valeurs MIN et MAX des autres pools comme le montre le tableau suivant :
|
Pool |
% MIN |
% MAX |
% MAX EFFECTIF |
% PARTAGE |
|
|---|---|---|---|---|---|
|
Interne |
0 |
100 |
100 |
0 |
MIN et MAX restent non applicables pour ce pool |
|
Défaut |
0 |
100 |
25 |
25 |
MAX EFF = min (100, 100 - (20 + 50 + 5)) % PARTAGE = MAX EFF - MIN |
|
Pool 1 |
20 |
100 |
45 |
25 |
MAX EFF = min (100, 100 - (50 + 5)) % PARTAGE = MAX EFF - MIN |
|
Pool 2 |
50 |
70 |
70 |
20 |
MAX EFF = min (70, 100 - (20 + 5)) % PARTAGE = MAX EFF - MIN |
|
Pool trois |
5 |
100 |
30 |
25 |
MAX EFF = min (100, 100 - (50 + 20)) % PARTAGE = MAX EFF - MIN |
Le choix des valeurs MAX et MIN des pools ainsi que leur nombre est ici très important et doit faire l'objet d'une étude préalable en fonction des besoins.
IV. Outils de monitoring▲
SQL Server met à disposition plusieurs outils pour connaître l'état et le comportement du gouverneur de ressources.
IV-A. Métadonnées▲
Le gouverneur de ressources possède ses propres métadonnées qui sont disponibles à partir de trois vues de catalogue :
- sys.resource_governor_configuration : retourne l'état de fonctionnement du gouverneur de ressources tel qu'il est stocké dans les métadonnées ;
- sys.resource_governor_resource_pools : retourne la configuration de chaque pool de ressources ainsi que ses paramètres ;
- sys.resource_governor_workload_groups : retourne la configuration de chaque groupe de charge de travail ainsi que ses paramètres.
3 vues de gestion dynamiques (DMV) concernent le gouverneur de ressources :
- sys.dm_ressource_governor_configuration : retourne l'état courant du gouverneur de ressources en mémoire. Cet état diffère de celui stocké dans les métadonnées de la vue système sys.resource_governor_configuration. En effet, un changement de configuration des paramètres du gouverneur de ressources nécessite obligatoirement sa reconfiguration. La colonne is_reconfiguration_pending de cette DMV est égale à 1 si une reconfiguration est nécessaire et indique par la même occasion une différence d'état avec celui stocké en mémoire ;
- sys.dm_resource_governor_resource_pools : retourne des informations concernant l'état et la configuration actuelle des pools ainsi que des données statistiques sur leur usage ;
- sys.dm_resource_governor_workload_groups : retourne des informations concernant l'état et la configuration des groupes de charge de travail ainsi que des statistiques sur leur usage.
Enfin, des informations concernant le gouverneur de ressources ont été ajoutées dans 6 vues de gestions dynamiques :
- sys.dm_exec_query_memory_grants : retourne des informations sur les requêtes qui ont acquis une allocation de mémoire ou qui requiert encore une allocation de mémoire pour leur exécution. Les requêtes qui n'ont pas besoin d'attendre une allocation ne sont pas répertoriées. Les colonnes group_id, pool_id, is_small et ideal_memory_kbont été rajoutées ;
- sys.dm_exec_query_resource_semaphores : retourne des informations concernant l'état actuel des sémaphores de ressources. On retrouve dans cette vue des informations générales sur l'allocation de mémoire pour l'exécution des requêtes ainsi que la quantité disponible pour le système. La colonne pool_id a été rajoutée dans cette vue ;
- sys.dm_exec_sessions : retourne des informations sur les sessions en cours. La colonne group_id a été rajoutée pour cette vue ;
- sys.dm_exec_requests : retourne des informations concernant chaque requête exécutée sur le serveur. La colonne group_id a été rajoutée pour cette vue ;
- sys.dm_exec_cached_plans : retourne des informations pour chaque plan d'exécution de requêtes stocké dans le cache pour une exécution plus rapide des requêtes. La colonne pool_id a été rajoutée pour cette vue ;
- sys.dm_os_memory_brokers : retourne des informations concernant les allocations internes effectuées par le moteur SQL. Cette vue est nouvelle sur SQL Server 2008. Les colonnes pool_id, allocations_db_per_sec, predicated_allocations_kb et overall_limit_kb peuvent concerner le gouverneur de ressources.
La corrélation des métadonnées du gouverneur de ressources avec les autres DMV existantes ouvre donc considérablement le champ d'analyse sur la consommation et le contrôle des ressources.
IV-B. SQL Profiler▲
SQL Profiler propose trois nouveaux événements qui concernent le gouverneur de ressources pouvant être capturés.
- CPU Threshold Exceeded : se déclenche seulement si le paramètre de groupe de charge de travail REQUEST_MAX_CPU_TIME_SEC a été activé. Dès lors, si l'exécution d'une requête dépasse le seuil fixé par ce paramètre, cet événement est déclenché.
- Preconnect :Starting et Preconnect :Completed : concernent la fonction de classification. Ceux-ci permettent de mesurer les temps de traitement de cette fonction lors d'une demande de connexion. Preconnect :Starting est déclenché quand la fonction de classification démarre et Preconnect :Completed est déclenché quand celle-ci termine le traitement de la demande.
IV-C. Compteurs de performance▲
Deux objets de compteurs ont été ajoutés. Ceux-ci sont également disponibles par l'intermédiaire de la DMV sys.dm_os_performance_counters.
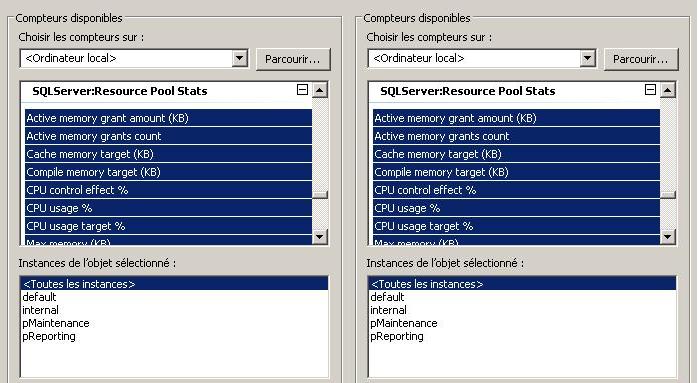
Il existe un objet pour chaque entité du gouverneur de ressources. (Un pour les pools de ressources et un pour les groupes de charge de travail.) Chaque objet possède son ensemble de compteurs qui permet la mesure et la visualisation de l'évolution de la consommation des ressources. De plus pour chaque objet de compteurs il existe également différentes instances représentant les pools de ressources ou les groupes de charge de travail existants. L'avantage certain du moniteur de performance est de pouvoir suivre de façon très visuelle ces évolutions de consommation de ressources.
IV-D. XEvents▲
Les événements étendus ou « Extended Events » sont une nouvelle fonctionnalité très puissante proposée dans SQL Server 2008. Celle-ci permet d'aller beaucoup plus loin dans le débogage que le permettait le profiler et se veut être son futur remplaçant. Ce système de trace permet d'indiquer des événements à suivre sous forme de session. Il existe une session qui est activée par défaut et qui se nomme system_health et cible un buffer circulaire dans lequel on peut récupérer des informations utiles au format XML. On y retrouve notamment :
- le texte de la commande SQL et le numéro de session d'une requête provoquant une erreur ayant une sévérité supérieure à 20 ;
- le texte de la commande SQL et le numéro de session d'une requête provoquant une erreur de type « mémoire » (par exemple 17803, 701, etc.) ;
- d'autres informations à propos de verrous légers supérieurs à 15s ou des verrous applications de plus de 30s et bien d'autres.
Nous verrons dans la suite de l'article comment les utiliser.
V. Étude pratique▲
Le paramétrage du gouverneur de ressources peut paraître difficile à première vue du fait des nombreux paramètres qu'il est possible de configurer. La 1re partie a été consacrée principalement à la présentation de l'architecture et des différents paramètres de configuration du gouverneur de ressources. Cette 2e partie se veut plus pratique pour permettre une meilleure compréhension des interactions et des comportements qui peuvent exister avec le gouverneur de ressources. Il existe de nombreux cas d'utilisation, mais le but de l'article n'est pas de tous les présenter. Nous prendrons un cas simple qui consiste à limiter les ressources en fonction d'un type de requête. Ce cas permettra de voir l'ensemble des concepts présentés dans la 1re partie. La situation sera donc la suivante.
Un administrateur de bases de données, pour les besoins d'une entreprise, doit mettre en place le gouverneur de ressources afin de limiter les ressources allouées à certains types de requêtes exécutées sur la base de données de production. Ces requêtes peuvent être classées en trois catégories :
- Application : les requêtes de cette catégorie sont celles de l'application principale de l'entreprise. Celles-ci doivent être prioritaires et doivent disposer d'un minimum de ressources pour garantir un fonctionnement correct de l'application afin de respecter les SLA ;
- Reporting Excel / Reporting Access : les requêtes de ces catégories sont des requêtes de Reporting exécutées depuis les deux applications Excel et Access. Ces requêtes sont par définition beaucoup plus consommatrices en ressource que celle de la 1re catégorie et peuvent engendrer actuellement des perturbations sur la base de données de production. De plus l'entreprise souhaite que les requêtes exécutées par l'application Excel soient prioritaires par rapport à celles exécutées par l'application Access ;
- Maintenance : les requêtes de cette catégorie sont des requêtes exécutées par certains administrateurs ou opérateurs de maintenance. Il arrive que parfois certains administrateurs exécutent par inadvertance certaines opérations de maintenance qui viennent perturber la production du fait d'une monopolisation excessive des ressources. Le souhait de l'entreprise est d'éviter au maximum ce genre de problème.
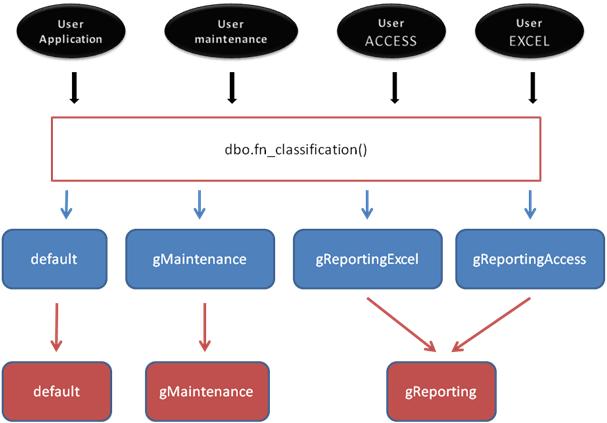
- Chaque type de requête est exécuté dans un contexte de sécurité spécifique. Les requêtes d'applications sont exécutées dans un contexte de sécurité de type Windows. Chaque utilisateur possède un compte Windows spécifique. Les requêtes de Reporting sont exécutées avec deux comptes de connexion SQL Server (excelreporting et accessreporting) ainsi que les requêtes de maintenance (maintenance).
On distingue ici clairement qu'il faudra trois pools de ressources pour répondre aux exigences de l'entreprise. Les requêtes de l'application principale étant les plus souvent exécutées seront toutes redirigées vers le pool par défaut. Les requêtes de Reporting, quant à elles, seront redirigées vers un pool nommé pReporting. Enfin les requêtes de maintenance seront redirigées vers un pool nommé pMaintenance.
Ensuite nous pouvons identifier quatre groupes de charge de travail : un groupe nommé gMaintenance pour les requêtes de maintenance qui sera associé au pool pMaintenance, un groupe nommé gReportingExcel pour les requêtes de Reporting de l'application Excel qui sera associé au pool pReporting, un groupe nommé gReportingAccess pour les requêtes de Reporting de l'application Access qui sera également associé au pool pReporting et enfin les requêtes d'application qui seront redirigées vers le groupe par défaut.
Le schéma de configuration d'utilisation du gouverneur de ressources sera donc le suivant :
V-A. Prérequis de test▲
Pour ce cas pratique, nous aurons besoin d'une base de données de test nommée db_ressource_governor ainsi que de trois comptes de connexion pour simuler chaque type d'application et de leurs utilisateurs de bases de données respectifs.
USE [master];
GO
-- Login pour les utilisateurs access
CREATE LOGIN accessreporting
WITH
PASSWORD=N'?cessreporting%',
CHECK_EXPIRATION=OFF,
CHECK_POLICY=OFF;
GO
-- Login pour les utilisateurs access
CREATE LOGIN excelreporting
WITH
PASSWORD=N'%excelreporting%',
CHECK_EXPIRATION=OFF,
CHECK_POLICY=OFF;
GO
-- Login utilisée pour la maintenance
CREATE LOGIN maintenance
WITH
PASSWORD=N'%maintenance%',
CHECK_EXPIRATION=OFF,
CHECK_POLICY=OFF;
GO
CREATE DATABASE db_resource_governor;
GO
USE db_resource_governor;
GO
CREATE USER accessreporting FROM LOGIN accessreporting;
GO
GRANT EXECUTE ON DATABASE::db_resource_governor TO accessreporting;
GO
sp_defaultdb 'accessreporting','db_resource_governor'
GO
CREATE USER excelreporting FROM LOGIN excelreporting;
GO
GRANT EXECUTE ON DATABASE::db_resource_governor TO excelreporting;
GO
sp_defaultdb 'excelreporting','db_resource_governor'
GO
CREATE USER maintenance FROM LOGIN maintenance;
GO
GRANT EXECUTE ON DATABASE::db_resource_governor TO maintenance;
GO
sp_defaultdb 'maintenance','db_resource_governor'
GOOn utilisera également l'utilitaire en ligne de commande SQLCmd qui sera appelé à partir d'un fichier batch. Nous aurons besoin de trois fichiers batch avec un fichier chaque type de requête et enfin d'un fichier d'instructions SQL qui sera utilisé par les trois fichiers de commande.
Chaque fichier de commande contiendra une ligne d'appel à SQLCmd :
- sqlcmd_application.bat
sqlcmd -E -i E:\test_rg\stress.sql- sqlcmd_accessreporting.bat
sqlcmd -U accessreporting -P %?cessreporting%% -i E:\test_rg\stress.sql- sqlcmd_excelreporting.bat
sqlcmd -U excelreporting -P %%excelreporting%% -i E:\test_rg\stress.sql- sqlcmd_maintenance.bat
sqlcmd -U maintenance -P %%maintenance%% -i E:\test_rg\stress.sqlLe fichier stress.sql contient la procédure TSQL suivante :
SET NOCOUNT ON;
DECLARE @i INT = 0;
DECLARE @result VARCHAR(1000);
WHILE @i < 10000000
BEGIN
SELECT @result = @@VERSION + CAST(RAND() AS VARCHAR(500))
SELECT @result = @@VERSION + CAST(RAND() AS VARCHAR(500))
SELECT @result = @@VERSION + CAST(RAND() AS VARCHAR(500))
SET @i = @i + 1;
ENDV-B. Configuration du gouverneur de ressources▲
Procédons maintenant à la configuration du gouverneur de ressources proprement dit. Par défaut celui-ci est désactivé et il est possible de le constater à l'aide de la vue système sys.resource_governor_configuration avec la valeur de la colonne is_enabled égale à 0. La 1re étape consiste à créer et configurer chaque entité du gouverneur de ressources.
V-B-1. La fonction de classification▲
Le script de configuration est le suivant :
USE master;
GO
CREATE FUNCTION dbo.classified_function()
RETURNS SYSNAME
WITH SCHEMABINDING
AS
BEGIN
RETURN
(
SELECT CASE SUSER_NAME()
WHEN 'excelreporting' THEN 'gReportingExcel'
WHEN 'accessreporting' THEN 'gReportingAccess'
WHEN 'maintenance' THEN 'gMaintenance'
ELSE 'Default'
END
)
END;
GOLa création de la fonction de classification se fait toujours dans le contexte de la base de données master. Il faut bien veiller à tester cette fonction pour résoudre les éventuels problèmes de syntaxe, de logique métier (par exemple une mauvaise redirection d'une demande vers un groupe de charge de travail ou un cas non prévu redirigé vers le groupe par défaut). Cette partie est importante et ne doit pas être négligée, car il représente le point d'entrée de toutes les demandes vers le gouverneur de ressources. Cependant pour pouvoir tester cette fonction le droit EXECUTE est nécessaire et tous les utilisateurs ne le possèdent pas en fonction de la sécurité mise en place sur le serveur. Une astuce consiste à créer et tester cette fonction sur une autre base de données dans un 1er temps et de créer sa version définitive dans la base master par la suite. L'option SCHEMABINDING est ici obligatoire et le type de données en sortie doit correspondre au type de paramètre utilisé en interne par le gouverneur de ressources. Dans le cas présent, la fonction système SUSERNAME() est utilisée pour identifier le login de connexion de la demande pour qualifier la redirection vers le bon groupe. D'autres fonctions système peuvent être utilisées comme expliqué précédemment dans l'article. Une qualification par type d'application obligerait l'utilisation de la fonction système APP_NAME() par exemple. La logique métier de la fonction peut être beaucoup plus complexe, mais il faudra faire attention aux problèmes de performance que cela peut engendrer.
Le script suivant permet de tester le bon fonctionnement de la fonction de classification créée précédemment :
-- utilisateur application principal
SELECT SUSER_NAME() AS session_name, dbo.classified_function() AS groupe_name;
GO
-- Utilisateur reporting avec Excel
EXECUTE AS LOGIN = 'excelreporting';
GO
SELECT SUSER_NAME() AS session_name, dbo.classified_function() AS groupe_name;
--
REVERT
GO
-- Utilisateur reporting avec Excel
EXECUTE AS LOGIN = 'accessreporting';
GO
SELECT SUSER_NAME() AS session_name, dbo.classified_function() AS groupe_name;
--
REVERT
GO
-- Utilisateur maintenance
EXECUTE AS LOGIN = 'maintenance';
GO
SELECT SUSER_NAME() AS session_name, dbo.classified_function() AS groupe_name;
--
REVERT
GOLe résultat est le suivant :
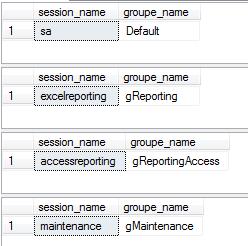
Une fois la fonction de classification créée et testée il faut indiquer au gouverneur de ressources d'utiliser cette fonction :
ALTER RESOURCE GOVERNOR
WITH
(
CLASSIFIER_FUNCTION = dbo.classified_function
);
GOV-B-2. Les pools de ressources▲
Dans un 1er temps, les pools d'applications seront créés avec les paramètres par défaut.
-- Pool de ressources pour les requêtes de maintenance
CREATE RESOURCE POOL pMaintenance
WITH
(
min_cpu_percent=0,
max_cpu_percent=100,
min_memory_percent=0,
max_memory_percent=100
);
GO
-- Pool de ressources pour les requêtes de reporting
CREATE RESOURCE POOL pReporting
WITH
(
min_cpu_percent=0,
max_cpu_percent=100,
min_memory_percent=0,
max_memory_percent=100
);
GOV-B-3. Les groupes de charge de travail▲
Les groupes de charge de travaillent seront également créés avec les paramètres par défaut
-- Groupe de charge de travail pour les requêtes de maintenance
CREATE WORKLOAD GROUP gMaintenance
USING pMaintenance;
GO
-- Groupe de charge de travail pour les requêtes de Reporting (Excel)
CREATE WORKLOAD GROUP gReportingExcel
USING pReporting;
GO
-- Groupe de charge de travail pour les requêtes de Reporting (Access)
CREATE WORKLOAD GROUP gReportingAccess
USING pReporting;
GOV-B-4. Activation du gouverneur de ressources▲
Le script suivant permet d'activer le gouverneur de ressources :
ALTER RESOURCE GOVERNOR RECONFIGURE;
GOV-B-5. Visualisation de la configuration du gouverneur de ressources▲
L'interrogation de la vue système sys.resource_governor_configuration donne l'état du gouverneur de ressources ainsi que l'id de la fonction de classification qu'il utilise.
SELECT *
FROM sys.resource_governor_configuration;
GOL'interrogation des vues système sys.resource_governor_resource_pools et sys.resource_governor_workload_groups donne la configuration des pools de ressources et des groupes de charge de travail créés précédemment.
SELECT
p.name AS pool_name,
p.min_cpu_percent AS pool_min_cpu_percent,
p.max_cpu_percent AS pool_max_cpu_percent,
g.name AS group_name,
g.importance AS group_importance
FROM sys.resource_governor_resource_pools AS p
INNER JOIN sys.resource_governor_workload_groups AS g
ON p.pool_id = g.pool_id;
GO… qui donne le résultat suivant :

La configuration du gouverneur de ressources étant terminée, nous utiliserons pour la suite du test le moniteur de performance pour visualiser le comportement de celui-ci par rapport à une charge de travail réelle. Pour cela, il est nécessaire d'utiliser deux objets de compteurs et les instances concernant les groupes de charge de travail et les pools de ressources créés et configurés précédemment. Le compteur CPU Usage % sera utilisé et nous exécuterons tour à tour chaque fichier batch pour simuler une charge de travail pour chaque type de requête.
Le tableau suivant récapitule les paramètres de configuration appliqués aux pools de ressources :
|
Pool |
% MIN |
% MAX |
% MAX EFFECTIF |
% PARTAGE |
|
|---|---|---|---|---|---|
|
Interne |
0 |
100 |
100 |
0 |
MIN et MAX non applicables pour ce pool |
|
Défaut |
0 |
100 |
100 |
100 |
MAX EFF = min (100, 100 - 0) % PARTAGE = MAX EFF - MIN |
|
pReporting |
0 |
100 |
100 |
100 |
MAX EFF = min (100, 100 - 0) % PARTAGE = MAX EFF - MIN |
|
pMaintenance |
0 |
100 |
100 |
100 |
MAX EFF = min (100, 100 - 0) % PARTAGE = MAX EFF - MIN |
Les valeurs des paramètres % MAX effectif pour chaque pool est ici de 100 % et ceci implique que les valeurs de partage pour chaque pool soit également de 100 %. Dans ce cas la répartition des ressources se fera équitablement en fonction de la charge de travail appliqué dans chaque pool de ressources.
V-C. Étude du comportement▲
Nous étudierons le comportement du gouverneur de ressources selon deux facettes qui sont l'évolution du partage des ressources dans les pools et les groupes de charge de travail.
V-C-1. 1er jeu de test▲
V-C-1-a. Les pools de ressources▲

Étape 1 : une requête d'application est exécutée. Celle-ci est redirigée vers le pool par défaut. On constate une augmentation de la consommation CPU à 50 % pour ce pool.
Étape 2 : une requête de Reporting est exécutée depuis l'application Access. Celle-ci est dirigée automatiquement vers le pool pReporting. On observe également une augmentation de la consommation en ressource de ce pool à 50 %. La totalité des ressources CPU sont partagées entre ces deux pools à cet instant.
Étape 3 : une 2e requête de Reporting est exécutée, mais cette fois depuis l'application Excel. Cette requête est également redirigée vers le pool pReporting. C'est en toute logique que la consommation CPU de ce pool devienne plus importante (75 %) que celle du pool par défaut (25 %) ce qui correspond à un ratio de 1 pour 3.
Étape 4 : une dernière requête de maintenance est exécutée. Le gouverneur de ressources modifie en conséquence la quantité de ressources CPU réservées au pool pReporting, car maintenant il faut compter avec celles que peut consommer le pool pMaintenance. Le gouverneur de ressources puise ces ressources dans la partie partagée du pool pReporting. Celle-ci passe donc à 50 %. En revanche, la consommation CPU du pool par défaut ne change pas, car pour le moment la répartition de la charge dans les pools se fait équitablement par le gouverneur de ressources.
V-C-1-b. Les groupes de charge de travail▲
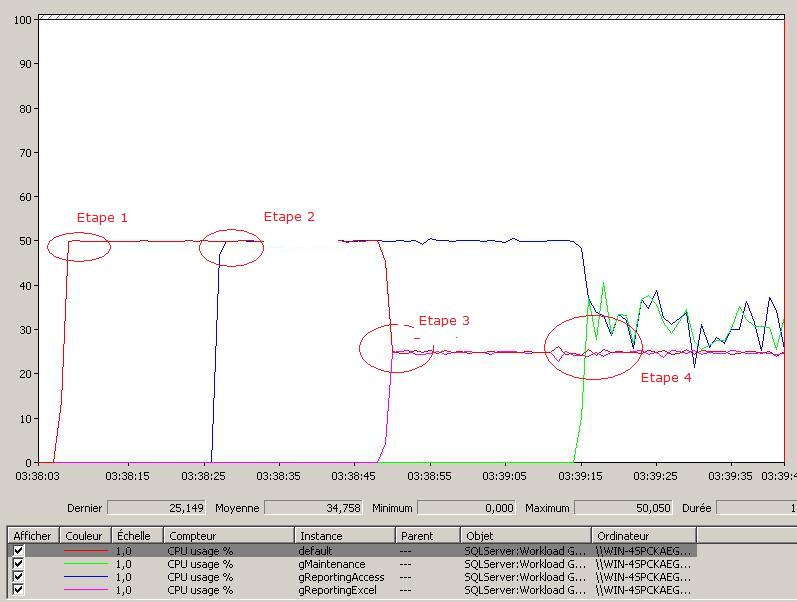
Étape 1 : une requête d'application est exécutée. Celle-ci est redirigée vers le groupe par défaut. On observe une augmentation des ressources consommées par le groupe de charge de travail par défaut à 50 %.
Étape 2 : une requête de Reporting depuis l'application Access est exécutée. Celle-ci est redirigée vers le groupe gReporting qui consomme à son tour des ressources équivalentes que le groupe par défaut. La totalité des ressources est maintenant monopolisée par ces deux groupes.
Étape 3 : une seconde requête de Reporting est exécutée depuis l'application Excel. Les ressources allouées au groupe par défaut ont diminué avec l'apparition d'une consommation supplémentaire de cette nouvelle requête. L'allocation totale pour les requêtes de Reporting est égale à 50 + 25 soit 75 %. Ce total correspond celui des ressources allouées pour le pool pReporting au même moment.
Étape 4 : une requête de maintenance est exécutée. La consommation supplémentaire dans le groupe gMaintenance oblige le gouverneur de ressources à diminuer celles allouées au groupe gReportingAccess. L'allocation des ressources est globalement la même pour les différents groupes (environ 25 %) à cet instant précis et sont comparables avec celles allouées aux différents pools de ressources.
Il est possible de connaître à tout moment la répartition des demandes dans les différents pools et groupes de charge de travail par l'intermédiaire des vues système du gouverneur de ressources sys.resource_governor_resource_pools , sys.resource_governor_workload_groups et les DMV / DMF sys.dm_exec_requests, sys.dm_exec_sql_text :
SELECT
p.name AS pool_name,
g.name AS group_name,
r.session_id,
t.text AS sql_txt
FROM sys.resource_governor_resource_pools AS p
INNER JOIN sys.resource_governor_workload_groups AS g
ON p.pool_id = g.pool_id
INNER JOIN sys.dm_exec_requests AS r
ON r.group_id = g.group_id
CROSS APPLY sys.dm_exec_sql_text(r.sql_handle) AS t
WHERE p.name <> 'internal'
ORDER BY p.name, g.name;
GOqui donne :

V-C-2. 2e jeu de test▲
Pour ce 1er jeu de test, nous avons vu le comportement du gouverneur de ressources avec les paramètres par défaut. On constate que la charge est répartie plus ou moins équitablement entre les différents groupes et les différents pools de ressources. Cependant la configuration actuelle ne répond pas aux exigences de notre étude pratique. Nous devons modifier la configuration du gouverneur de ressources.
Le tableau suivant nous permettra de dimensionner des valeurs MIN et MAX plus adaptées pour les pools de ressources :
|
Pool |
% MIN |
% MAX |
% MAX EFFECTIF |
% PARTAGE |
|
|---|---|---|---|---|---|
|
Interne |
0 |
100 |
0 |
0 |
MIN et MAX non applicables pour ce pool |
|
Défaut |
50 |
100 |
50 |
50 |
MAX EFF = min (100, 100 - 0) % PARTAGE = MAX EFF - MIN |
|
pReporting |
0 |
50 |
50 |
50 |
MAX EFF = min (50, 100 - 50) % PARTAGE = MAX EFF - MIN |
|
PMaintenance |
0 |
50 |
50 |
50 |
MAX EFF = min (70, 100 - 50) % PARTAGE = MAX EFF - MIN MAX EFF = min (70, 100 - 50) % PARTAGE = MAX EFF - MIN |
Quelques changements sont à noter :
- Pool par défaut : on réserve un minimum de 50 % de ressources CPU en cas de contention ;
- Pool pReporting : on paramètre la valeur MAX du pool à 50 % pour être certain qu'une ou plusieurs requêtes consommatrices ne viennent pas perturber la production ;
- les valeurs de partage des pools ont également changé. Celles-ci ont diminué de 50 % pour les deux pools utilisateurs.
Le script suivant permet de configurer les pools de ressources conformément au tableau récapitulatif précédent :
-- Modification max cpu pour le pool par défaut
ALTER RESOURCE POOL [default]
WITH
(
min_cpu_percent=50
);
GO
-- Modification max cpu pour le pool pReporting
ALTER RESOURCE POOL pReporting
WITH
(
max_cpu_percent=50
);
GO
-- Modification max cpu pour le pool pMaintenance
ALTER RESOURCE POOL pMaintenance
WITH
(
max_cpu_percent=50
);
GO
-- Modification de priorité pour le groupe de requêtes en provenance de Access
ALTER WORKLOAD GROUP gReportingAccess
WITH
(
importance = LOW
);
GO
-- Reconfiguration du gouverneur de ressources avec les nouveaux paramètres
ALTER RESOURCE GOVERNOR RECONFIGURE;
GOLa valeur d'importance pour le groupe de charge de travail gReportingAccess est à LOW. Ce paramétrage a été défini afin de satisfaire le point suivant : « les requêtes de l'application Excel sont prioritaires par rapport aux requêtes de l'application Excel ».
Pour ce 2e test, chaque type de requête sera exécuté dans le même ordre que précédemment et ceci deux fois pour atteindre une consommation de ressources plus représentative.
V-C-2-a. Les pools de ressources▲

Étape 1 : les deux requêtes d'applications sont exécutées. On observe une monopolisation immédiate des ressources CPU à 100 % pour le pool par défaut.
Étape 2 : les deux requêtes de Reporting pour l'application Access sont exécutées. Les ressources allouées au pool d'application ont diminué au profit du pool pReporting. La consommation CPU est maintenant équilibrée entre ces deux pools. (Environ 50 %.)
Étape 3 : l'exécution de deux nouvelles requêtes de Reporting pour l'application Excel augmente la consommation des ressources dans le pool pReporting un bref instant. Cependant les nouveaux paramètres configurés pour le pool par défaut stipulent que lorsqu'il y existe une contention CPU le gouverneur de ressources doit garantir que 50 % des ressources CPU soient utilisées par les requêtes de ce pool. C'est ce que l'on observe à présent : progressivement la consommation des ressources se stabilise et on observe à nouveau que la consommation des ressources CPU est équilibrée. (50 % pour le pool par défaut et 50 % pour le pool pReporting alors que la consommation dans ce dernier est deux fois plus importante que celle du pool par défaut.)
Étape 4 : l'exécution des deux requêtes de maintenance ne diminue toujours pas les ressources allouées au pool par défaut qui est toujours de 50 %. En revanche les ressources allouées au pool pReporting ont diminué au profit du pool pMaintenance. La consommation est deux fois plus importante dans le pool pReporting que dans le pool pMaintenance (quatre requêtes de Reporting contre deux de maintenance). Cela peut expliquer le fait que les ressources CPU allouées au pool pReporting soient supérieures à celles réservées au pool pMaintenance. Le calcul est en fait assez simple : il reste 50 % de ressources CPU disponibles pour les deux pools pReporting et pMaintenance car le reste des ressources est alloué au pool par défaut. Six requêtes sont exécutées au total dans ces deux pools. On peut en déduire que la consommation d'une requête est de 50 / 6 soit environ 8.3 %. Pour le pool pReporting nous obtenons une consommation globale de 8.3 X 4 = 33.2 % et pour le pool pMaintenance nous obtenons une consommation globale de 8.3 * 2 = 16.6 % ce qui correspond aux arrondis près à une consommation globale de 50 %. Nous pouvons vérifier ces valeurs sur le graphe d'évolution des ressources des pools de ressources ci-dessus.
V-C-2-b. Les groupes de charge de travail▲
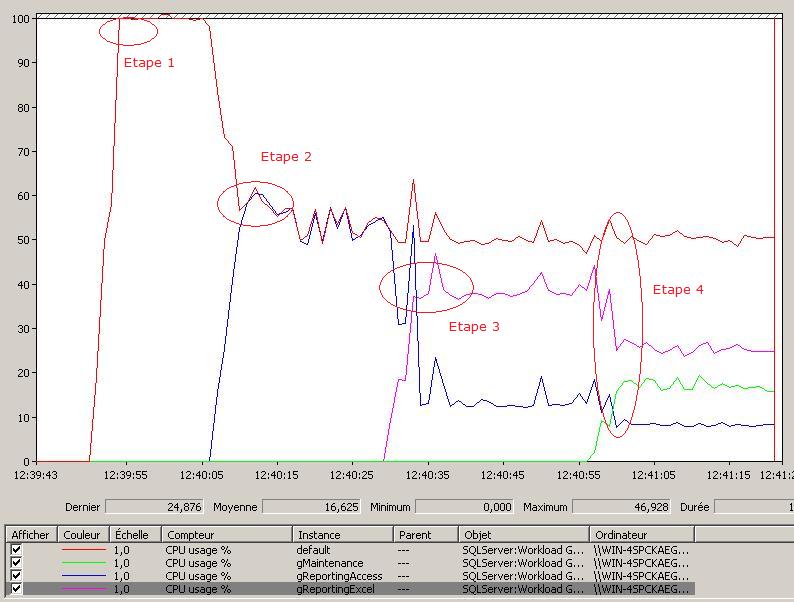
Étape 1 : l'augmentation soudaine de la consommation CPU à 100 % correspond à l'exécution des deux requêtes d'application dans le groupe par défaut.
Étape 2 : l'exécution des deux requêtes de Reporting pour l'application Access fait chuter la quantité de ressources disponibles à 50 % pour le groupe par défaut. La consommation des ressources CPU dans le groupe gReporting est également de 50 %.
Étape 3 : on peut noter plusieurs changements à ce stade. Premièrement on constate que la quantité de ressources CPU est toujours égale à 50 % pour le groupe par défaut à cause de valeur du paramètre MIN_CPU_PERCENT appliquée pour le pool par défaut comme nous l'avons expliqué un plus haut dans l'article. Deuxièmement l'exécution des deux requêtes de Reporting pour l'application Excel fait chuter considérablement la quantité de ressources allouées précédemment pour les requêtes de l'application Access (On passe de 50 % à environ 15 %). Ce comportement est dû à la valeur du paramètre IMPORTANCE des groupes gReportingAccess (LOW) et gReportingExcel (MEDIUM). Ce paramètre d'importance permet de prioriser les requêtes d'un groupe par rapport à un ou d'autre(s) groupe(s) d'un même pool de ressources par le biais des ordonnanceurs. Cette priorisation se matérialise sous la forme d'un ratio composé par les valeurs de paramètre d'importance de chaque groupe. Dans notre cas ce ratio est de 1:3. Il indique à l'ordonnanceur la façon de prioriser une requête de Reporting pour l'application Excel par rapport à une requête de Reporting pour l'application Access en fonction des ressources disponibles.
Étape 4 : l'apparition d'une charge de travail dans le groupe gMaintenance avec l'exécution des deux requêtes de maintenance fait diminuer la quantité de ressources disponibles dans les groupes gReportingExcel et gReportingAccess, mais toujours pas celles du groupe par défaut. Le calcul des valeurs MIN et MAX est équivalent à celui pour les pools de ressources. On remarque également que les ressources disponibles pour ces deux derniers groupes restent toujours proportionnelles à l'allocation globale en fonction du ratio déterminé par les paramètres d'importance des groupes
Ce 2e test met en évidence qu'un changement de valeur d'un paramètre d'une entité du gouverneur de ressources peut influencer de façon plus ou moins importante sur les autres valeurs des autres entités et sur la consommation de ressources qui en résulte. Il est important de bien prendre en considération les contraintes d'entreprises et de se poser les bonnes questions quant aux différentes valeurs à choisir.
V-C-3. Autres options▲
Jusqu'à présent nous avons principalement observé l'influence du gouverneur de ressources sur les ressources CPU. La suite du test consistera à observer le comportement du gouverneur de ressources face au paramétrage des options restantes pour les groupes de charge de travail.
V-C-3-a. MAX_MEMORY_PERCENT▲
Le compteur de performance « Max memory (KB) » permet de visualiser la consommation de ressources mémoire pour chaque instance de pool du gouverneur de ressources.
Voici ce que nous observons avec les paramètres par défaut :

Le serveur utilisé pour les tests dispose d'environ 2 Go de mémoire virtuelle pour les processus utilisateurs. La DMV sys.dm_os_sys_info permet de le vérifier avec la colonne virtual_memory_in_bytes La quantité de mémoire pour chaque pool est équivalente pour le moment, car les paramètres MIN_MEMORY_PERCENT et MAX_MEMORY_PERCENT sont configurés avec les valeurs par défaut. Le gouverneur de ressources répartit logiquement les ressources mémoire entre ses différents pools. Comme nous l'avons expliqué un peu plus haut dans l'article, il faut faire attention à la configuration des valeurs de ces paramètres. En effet le paramètre MIN_MEMORY_PERCENT indique au gouverneur de ressources de réserver une quantité de mémoire pour un pool et ceci même si aucune activité n'existe à l'intérieur de celui-ci. Pour le vérifier, nous allons changer la valeur du paramètre MIN_MEMORY_PERCENT du pool par défaut à 50 % ce qui signifie que nous réservons 50 % de la mémoire pour les requêtes d'application.
-- Réservation 50 % ressource mémoire pour le groupe par défaut
ALTER RESOURCE POOL [default]
WITH
(
min_memory_percent=50
);
GO
-- Reconfiguration du gouverneur de ressources
ALTER RESOURCE GOVERNOR RECONFIGURE;
GOLes nouvelles valeurs de compteurs de performances sont :

On constate un changement de la quantité de mémoire réservée pour chaque pool. Le pool par défaut possède maintenant une quantité de mémoire égale au double de la somme des quantités de mémoire réservées pour les deux autres pools de ressources pMaintenance et pReporting. L'option MAX_MEMORY_PERCENT permet, quant à elle, de spécifier la quantité maximum de ressources mémoire pour l'ensemble des requêtes d'un pool. Une valeur trop faible pour ce paramètre peut provoquer des problèmes d'exécution pour l'ensemble des requêtes d'un pool dus à une insuffisance de ressources mémoire. Changeons la valeur de ce paramètre pour le pool de ressources pMaintenance.
-- Réservation 50 % ressources mémoire pour le groupe par défaut
ALTER RESOURCE POOL [pMaintenance]
WITH
(
max_memory_percent=2
);
GO
-- Reconfiguration du gouverneur de ressources
ALTER RESOURCE GOVERNOR RECONFIGURE;
GOLes nouvelles valeurs de compteurs de performances sont :

La quantité maximum de mémoire pour le pool pMaintenance est maintenant de 13 MB.
V-C-3-b. GROUP_MAX_REQUESTS▲
Le paramètre GROUP_MAX_REQUESTS permet de limiter le nombre de requêtes concurrentes s'exécutant dans un même groupe de charge de travail. Si l'on reprend notre cas d'étude, nous voulons maintenant qu'une seule requête de type Reporting soit exécutée à la fois pour l'application Excel pour ne pas perturber le fonctionnement global de la production.
-- Restriction d'exécution d'une seule requête à la fois pour
-- le groupe gReportingExcel
ALTER WORKLOAD GROUP gReportingExcel
WITH
(
group_max_requests=1
);
GO
-- Reconfiguration du gouverneur de ressources
ALTER RESOURCE GOVERNOR RECONFIGURE;
GOExécutons deux requêtes de Reporting pour l'application Excel. Pour vérifier le nombre de requêtes mises en file d'attente dans ce groupe de charge de travail il existe plusieurs solutions :
- à l'aide de la DMV sys.dm_resource_governor_workload_groups
SELECT
name,
total_request_count,
total_queued_request_count
FROM sys.dm_resource_governor_workload_groups
WHERE name = 'gReportingExcel';
GO… qui donne le résultat suivant :

Il y a deux requêtes actives dans le groupe de charge de travail gReportingExcel dont une est mise dans la file d'attente ;
- à l'aide de la DMV sys.dm_resource_governor_workload_groups et sys.dm_exec_requests
SELECT
g.name,
r.start_time,
r.status,
r.command,
t.text
FROM sys.dm_resource_governor_workload_groups AS g
INNER JOIN sys.dm_exec_requests AS r
ON g.group_id = r.group_id
OUTER APPLY sys.dm_exec_sql_text(r.sql_handle) AS t
WHERE g.name = 'gReportingExcel';
GO… qui donne le résultat :

Il existe qu'une seule requête de Reporting en train de s'exécuter (Statut running).
V-C-3-c. MAXDOP▲
Cette option, comme nous l'avons expliqué un peu plus haut dans l'article, permet de définir le degré de parallélisme maximum que pourra utiliser une requête. À l'instar de l'option MAXDOP utilisée par les indicateurs de requêtes celle-ci sérialise les demandes candidates à une exécution parallèle. Pour le vérifier, paramétrons la valeur de ce paramètre à 1 pour le groupe de charge de travail gReportingAccess.
Pour pouvoir générer un plan d'exécution parallèle, créons un jeu de données assez volumineux. Le script suivant crée une table de test et la remplit à un jeu de données consistant :
USE db_resource_governor;
GO
CREATE TABLE dbo.test_maxdop
(
id INT IDENTITY(1,1) NOT NULL,
category VARCHAR(25) NOT NULL,
closed_dt DATETIME NOT NULL
);
GO
DECLARE @i INT = 0;
WHILE @i < 1000000
BEGIN
IF @i < 333333 INSERT dbo.test_maxdop (category, closed_dt)
VALUES ('category' + CAST(FLOOR(RAND() * 10) AS VARCHAR(2)), DATEADD(MONTH, FLOOR(RAND() * 10), '20070101'));
IF @i > 333333 AND @i <= 666666 INSERT dbo.test_maxdop (category, closed_dt)
VALUES ('category' + CAST(FLOOR(RAND() * 10) AS VARCHAR(2)), DATEADD(MONTH, FLOOR(RAND() * 10), '20080101'));
IF @i > 666666 INSERT dbo.test_maxdop (category, closed_dt)
VALUES ('category' + CAST(FLOOR(RAND() * 10) AS VARCHAR(2)), DATEADD(MONTH, FLOOR(RAND() * 10), '20090101'));
SET @i +=1;
END;
GOOctroyons également les droits de lecture à l'utilisateur accessreporting pour la base de données db_resource_governor :
GRANT SELECT ON DATABASE::db_resource_governor TO accessreporting;
GOIl ne reste plus qu'à exécuter la requête suivante sans aucun paramétrage du groupe de charge de travail pour le moment :
SELECT
YEAR(closed_dt) AS annee,
category,
COUNT(*) AS nb
FROM dbo.test_maxdop
GROUP BY YEAR(closed_dt), category;
GOCette requête génère un plan de requête parallèle. (L'option de serveur max degree of parallelism doit être configuré pour autoriser le parallélisme.) Pour le vérifier, il suffit de visualiser le plan estimé d'exécution de cette requête. Il est également possible de le constater en vérifiant que cette requête utilise plusieurs threads parallèles durant son exécution à l'aide des DMV sys.dm_resource_governor_workload_groups et sys.dm_exec_requests :
SELECT
g.name,
g.active_parallel_thread_count,
r.start_time,
r.status,
r.command,
t.text
FROM sys.dm_resource_governor_workload_groups AS g
INNER JOIN sys.dm_exec_requests AS r
ON g.group_id = r.group_id
CROSS APPLY sys.dm_exec_sql_text(r.sql_handle) AS t
WHERE g.name = 'gReportingAccess';
GO… qui donne le résultat suivant :

À présent, modifions la valeur du paramètre MAXREQUEST à 1 pour le groupe gReportingAccess :
-- Modification du paramètre maxdop à 1 pour les requêtes du groupe gReportingAccess
ALTER WORKLOAD GROUP gReportingAccess
WITH
(
max_dop = 1
);
GO
-- Reconfiguration du gouverneur de ressources
ALTER RESOURCE GOVERNOR RECONFIGURE;
GONote : il faut vider le cache de procédure avant de relancer la requête (ce qui aura pour effet de générer un nouveau plan d'exécution) :
DBCC DROPCLEANBUFFERS;
GO
SELECT
g.name,
g.active_parallel_thread_count,
r.start_time,
r.status,
r.command,
t.text,
p.query_plan
FROM sys.dm_resource_governor_workload_groups AS g
INNER JOIN sys.dm_exec_requests AS r
ON g.group_id = r.group_id
CROSS APPLY sys.dm_exec_sql_text(r.sql_handle) AS t
CROSS APPLY sys.dm_exec_query_plan(r.plan_handle) AS p
WHERE g.name = 'gReportingAccess';
GO… qui donne le résultat suivant :

Cette fois il n'y a plus d'utilisation de threads parallèles pour l'exécution de la même requête. Si on regarde le plan d'exécution réel de la requête au format XML, on constate pourtant que celui-ci a été généré en tant que plan parallèle :
<QueryPlan DegreeOfParallelism="0" ?>Cependant si l'on regarde un peu plus loin au niveau du nœud RunTimeInformation, on s'aperçoit que celui-ci ne comporte qu'un seul thread alors que pour un plan d'exécution parallèle classique il en existe plusieurs. Notre requête a donc bien été sérialisée. Par conséquent chaque opération parallèle s'exécute donc une à une et à la suite.
<RunTimeInformation>
<RunTimeCountersPerThread Thread="0" ActualRows="30" ActualEndOfScans="1" ActualExecutions="1" />
</RunTimeInformation>Note : pour pouvoir afficher le plan d'exécution réel de la requête de Reporting en tant qu'utilisateur reportingAccess il faut lui donner les droits adéquats :
GRANT SHOWPLAN TO accessreporting;
GOV-C-3-d. REQUEST_MAX_MEMORY_GRANT_PERCENT▲
Ce paramètre définit la quantité de mémoire de travail virtuelle maximum allouée pour l'exécution d'une requête pour d'éventuelles opérations de tri ou de jointure par exemple. Une mauvaise configuration peut générer des problèmes de disponibilité de ressources mémoire pour les requêtes du groupe concerné. Prenons le cas extrême et paramétrons une valeur égale à 0, ce qui signifie qu'aucune opération de tri ou de jointure n'est permise pour les requêtes du groupe :
-- Modification valeur quantité max de mémoire allouée pour l'exécution d'une requête
ALTER WORKLOAD GROUP gReportingAccess
WITH
(
request_max_memory_grant_percent = 0
);
GO
-- Reconfiguration du gouverneur de ressources
ALTER RESOURCE GOVERNOR RECONFIGURE;
GOExécutions la requête suivante sur la table test_maxdop en tant qu'utilisateur accessreporting :
SELECT
YEAR(closed_dt) AS annee,
category,
COUNT(*) AS nb
FROM dbo.test_maxdop
GROUP BY YEAR(closed_dt), category;
GOLe message d'erreur suivant apparaît :
Msg 8657, Level 17, State 1, Line 2 Could not get the memory grant of 1280 KB because it exceeds the maximum configuration limit in workload group 'gReportingAccess' (258) and resource pool 'pReporting' (257). Contact the server administrator to increase the memory usage limit.
Que s'est-il passé ? La requête précédente ne peut pas utiliser certains opérateurs relatifs à la clause GROUP BY du fait de la configuration de l'option request_max_memory_grant_percent. Celle-ci ne peut donc pas s'exécuter et le moteur SQL déclenche une erreur.
On peut également récupérer cette erreur en utilisant les événements étendus en utilisation une session par défaut system_health:
SELECT CAST(t.target_data AS XML)
FROM sys.dm_xe_session_targets AS t
INNER JOIN sys.dm_xe_sessions AS s
ON s.[address] = t.event_session_address
WHERE s.name = 'system_health';
GOLe résultat se présente sous une forme XML :

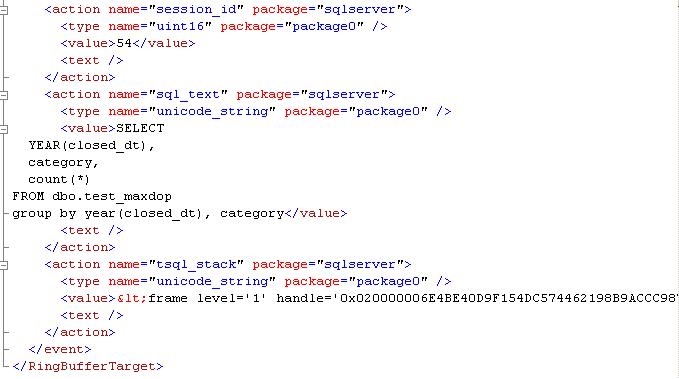
On retrouve ici les éléments importants comme le numéro d'erreur, la sévérité, le message d'erreur et la requête qui a déclenché l'erreur.
V-C-3-e. REQUEST_MAX_CPU_TIME_SEC▲
Ce paramètre détermine la limite de temps durant laquelle une requête doit pouvoir s'exécuter. Si cette limite est atteinte un événement CPU Threshold exceeded est déclenché. Nous allons capturer cet événement grâce au Profiler de SQL Server.
On configure tout d'abord le paramètre REQUEST_MAX_CPU_TIME à une seconde pour le groupe gReporingExcel pour permettre un déclenchement certain de l'événement :
-- Modification temps CPU maximum accordé pour l'exécution d'une requête
ALTER WORKLOAD GROUP gReportingExcel
WITH
(
request_max_cpu_time_sec = 1
);
GO
-- Reconfiguration du gouverneur de ressources
ALTER RESOURCE GOVERNOR RECONFIGURE;
GOOn exécute ensuite la requête suivante avec l'utilisateur excelreporting :
SET NOCOUNT ON;
DECLARE @i INT = 0;
DECLARE @result VARCHAR(1000);
WHILE @i < 10000000
BEGIN
SELECT @result = @@VERSION + CAST(RAND() AS VARCHAR(500))
SELECT @result = @@VERSION + CAST(RAND() AS VARCHAR(500))
SELECT @result = @@VERSION + CAST(RAND() AS VARCHAR(500))
SET @i = @i + 1;
END;
GOAprès avoir lancé le profiler voici le résultat obtenu :
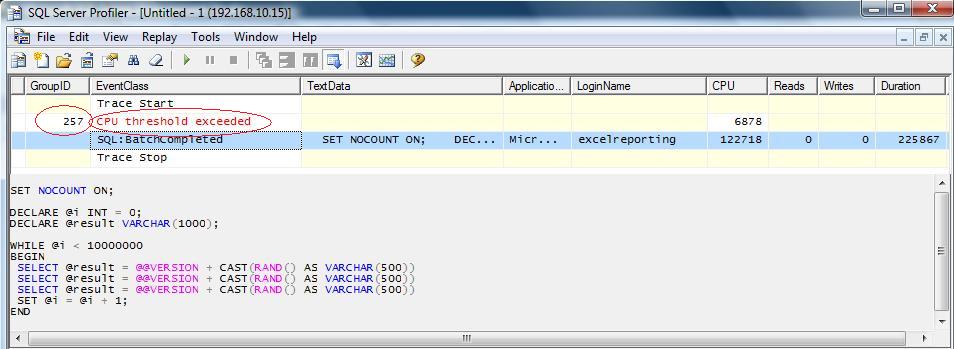
L'événement CPU Threshold exceeded est bien déclenché. La requête précédente en est à l'origine. Celle-ci a bien été qualifiée dans le groupe gReportingExcel. (GroupID = 257). On peut le vérifier également à l'aide la requête suivante :
SELECT
name,
request_max_cpu_time_sec
FROM sys.resource_governor_workload_groups
WHERE group_id = 257;
GOV-C-3-f. Événements Preconnect : Starting et Preconnect : Completed▲
Lors de l'implémentation d'une fonction de classification il est intéressant de mesurer ses performances, car rappelons-le, elle est le point d'entrée de toutes les demandes vers le gouverneur de ressources. Cette fonction doit être, par conséquent, la plus simple et la plus efficace possible. Ces deux événements permettent d'en vérifier les performances de cette fonction en récupérant sa date de début et sa date de fin d'exécution.
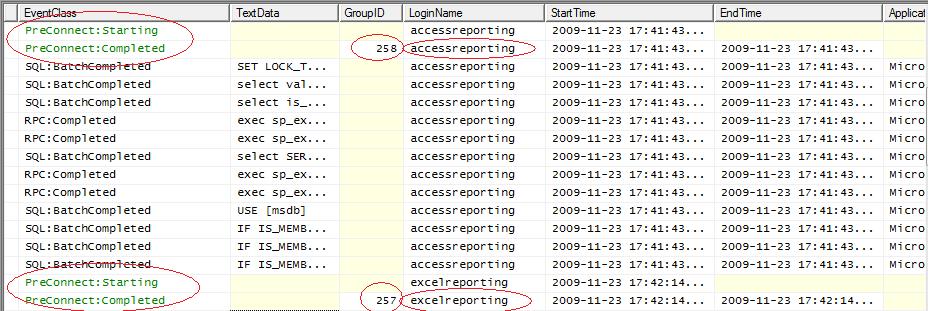
Une chose importante est à retenir : une fois qu'une demande de connexion a été qualifiée par la fonction de classification celle-ci est dirigée vers le groupe de charge de travail adéquat. Cette action est définitive pour la demande concernée. En d'autres termes, la qualification d'une demande ne peut pas changer au cours de son existence.
V-D. Désactivation du gouverneur de ressources▲
L'option DISABLE de la commande ALTER RESOURCE GOVERNOR permet de désactiver celui-ci :
ALTER RESOURCE GOVERNOR DISABLE;
GOLa désactivation du gouverneur de ressources a pour effet de :
- désactiver la fonction de classification ;
- qualifier les nouvelles connexions directement dans le pool par défaut ;
- qualifier les demandes initiées par le système dans le pool interne ;
- réinitilialiser les paramètres des groupes de charge de travail et pools de ressources présents à ce moment-là.
V-E. Réinitialisation des données de statistiques▲
L'option RESET STATISTICS de la commande ALTER RESOURCE GOVERNOR permet de réinitialiser les données de statistiques des groupes de charge de travail et des pools de ressources.
ALTER RESOURCE GOVERNOR RESET STATISTICS;
GOVI. MÉTADONNES ET GOUVERNEUR DE RESSOURCES▲
Les métadonnées propres au gouverneur de ressources qui se présentent sous la forme de vues système et DMV permettent de s'informer sur l'état et l'évolution des ressources. Voici une liste non exhaustive de questions auxquelles il est possible de répondre à l'aide des vues système et DMV dédiées au gouverneur de ressources.
- Quelle est la répartition des utilisateurs et des requêtes actives pour chaque pool de ressources et groupe de charge de travail ?
SELECT
w.group_id,
w.name AS groupe_name,
active_request_count,
COALESCE(s.nb_users, 0) AS nb_users
FROM sys.dm_resource_governor_workload_groups AS w
LEFT JOIN
(
SELECT
group_id,
COUNT(*) AS nb_users
FROM sys.dm_exec_sessions
GROUP BY group_id
) AS s
ON w.group_id = s.group_id;
GO- Quelle est la consommation CPU moyenne d'une requête par pool de ressources ?
SELECT
p.name,
COALESCE(SUM(p.total_cpu_usage_ms),0) AS total_cpu_usage_ms,
COALESCE(SUM(g.total_request_count),0) AS total_request_count,
CASE WHEN SUM(g.total_request_count) > 0
THEN SUM(p.total_cpu_usage_ms) / SUM(g.total_request_count)
ELSE 0
END AS avg_cpu_per_requests_ms
FROM sys.dm_resource_governor_resource_pools AS p
INNER JOIN sys.dm_resource_governor_workload_groups AS g
ON p.pool_id = g.pool_id
WHERE p.pool_id > 1
GROUP BY p.name;
GO- Quelle est l'utilisation globale des ressources par pool ?
WITH total_resources
AS
(
SELECT
SUM(total_cpu_usage_ms) AS total_cpu_usage_ms,
SUM(cache_memory_kb) AS total_cache_memory_kb,
SUM(compile_memory_kb) AS total_compile_memory_kb,
SUM(used_memory_kb) AS total_used_memory_kb
FROM sys.dm_resource_governor_resource_pools
)
SELECT
p.name AS pool_name,
p.total_cpu_usage_ms * 100.0 / t.total_cpu_usage_ms AS total_cpu_usage,
p.cache_memory_kb * 100.0 / t.total_cache_memory_kb AS cache_memory,
p.compile_memory_kb * 100.0 / t.total_compile_memory_kb AS compile_memory,
p.used_memory_kb * 100.0 / t.total_used_memory_kb AS used_memory
FROM sys.dm_resource_governor_resource_pools AS p
CROSS JOIN total_resources AS t;
GO- Quelle est la répartition des requêtes par rapport aux ordonnanceurs et aux groupes de charges de travail actuellement ?
SELECT
r.session_id,
wg.name AS group_name,
t.scheduler_id,
r.status
from sys.dm_exec_requests AS r
INNER JOIN sys.dm_os_tasks AS t
ON r.task_address = t.task_address
INNER JOIN sys.dm_resource_governor_workload_groups AS wg
ON r.group_id = wg.group_id
WHERE r.session_id > 50;
GOVII. Inconvénients▲
Il existe certains inconvénients quant à l'utilisation du gouverneur de ressources :
- le gouverneur de ressources n'est disponible qu'à partir de la version Entreprise de SQL Server 2008 ;
- le gouverneur de ressources ne gère que l'instance sur laquelle il se trouve ;
- le gouverneur de ressources ne gère uniquement que les ressources du moteur SQL. Les autres composants tels que SSAS ou SSRS ne sont pas gérés ;
- nous n'avons parlé que des ressources mémoire et CPU mais pas des ressources I/O disques. Dans la version actuelle, le gouverneur de ressources ne sait pas gérer ce type de ressources.
VIII. Conclusion▲
Le gouverneur de ressources constitue une avancée majeure dans le domaine du contrôle de la disponibilité des ressources. Les entreprises doivent pouvoir prédire, anticiper et contrôler les différentes ressources partagées et consommées sur le serveur dans les phases de test et de production. Le gouverneur de ressources permet de répondre à cela en offrant à l'administrateur de bases de données un panel d'outils de configuration et de monitoring. Les prochaines évolutions de cet outil, espérons-le, ne peuvent être que prometteuses !!